This article simulates various docker and k8s questions asked by the interviewer , aiming to improve the interview pass rate. Welcome to discuss in the comment area and make progress simultaneously.
What is the working principle of docker? Let’s talk about it.
Docker operates on a Client-Server model. The Docker daemon, which operates on the host system, is responsible for managing containers. It accepts commands from the Docker client and oversees the execution of containers on the host.
What are the major parts of docker?
A complete Docker setup comprises the following components:
- Docker Client: This client offers users a set of executable commands to interact with the Docker daemon. Users utilize these commands to perform various operations on Docker.
- Docker Daemon: The Docker daemon, running in the background on the host system, awaits requests from the client. It processes these requests and manages the Docker containers accordingly.
- Docker Image: Docker images serve as templates for Docker containers. When executed, these images are transformed into running Docker containers.
- Docker Container: Docker containers are system-level entities that function as isolated services, each having its own IP address and directory structure. Containers run based on corresponding Docker images. If an image isn’t available locally, Docker fetches it from the image repository.
Docker operates on a client-server architecture, utilizing remote APIs for managing and creating Docker containers. The relationship between containers and images can be likened to that between objects and classes in object-oriented programming.
What is the difference between docker and traditional virtual machines?
- Traditional virtual machines require installing the entire operating system before running business applications, resulting in startup times of several minutes. In contrast, Docker utilizes images to quickly launch business containers within seconds.
- Docker demands fewer resources as it virtualizes at the operating system level. Docker containers interact with the kernel with minimal performance overhead, while virtual machines consume more resources by running complete operating systems.
- Docker is lightweight due to its architecture’s ability to share a kernel and application library, resulting in minimal memory usage. In the same hardware environment, Docker can run more images than virtual machines, optimizing system utilization.
- Compared to virtual machines, Docker provides weaker isolation, operating at the process level rather than system-level isolation.
- Docker’s security is also less robust, as container root privileges are equivalent to host root privileges. In contrast, virtual machines maintain separate root permissions, utilizing hardware isolation technologies to prevent breaches.
- Docker’s centralized management tools are still evolving, lacking maturity compared to established virtualization technologies like VMware vCenter.
- Docker achieves high availability through rapid redeployment, while virtualization offers mature mechanisms such as load balancing, fault tolerance, and data protection, ensuring business continuity.
- Docker containers can be created within seconds, facilitating rapid iteration and saving time in development, testing, and deployment compared to virtual machine creation, which takes minutes.
- Virtual machines ensure environment consistency through mirroring, whereas Docker records container construction processes in Dockerfiles, enabling rapid distribution and deployment within clusters.
What are the three core concepts of docker technology?
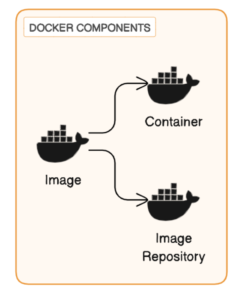
- Image: An image is a lightweight, standalone software package containing everything necessary to execute a particular software. It encapsulates the application along with its configuration dependencies, forming a deployable operating environment. This includes code, runtime libraries, environment variables, and configuration files. Essentially, an image is a packaged runtime environment.
- Container: A container is an instance created from an image. It represents the operational environment after an image is executed. Containers are where business applications are actually executed. Analogously, if we compare images to classes in a program, containers can be seen as objects.
- Image Repository: An image repository, also known as an image warehouse, is a storage location for images. After development and operations engineers package the images, they upload them to the repository. Users with appropriate permissions can then pull these images to run containers.
The centos image is several gigabytes, but the docker centos image is only a few hundred megabytes. Why is this?
A complete Linux operating system consists of the Linux kernel and the root file system (rootfs), which includes familiar directories like /dev, /proc, and /bin. Traditional Linux distributions like CentOS also come with additional optional software, services, and graphical desktop environments, resulting in larger image sizes, often several gigabytes in size.
However, when it comes to container images, all containers share the Linux kernel of the host machine. Docker images, in particular, only require a small rootfs containing essential commands, tools, and programs. These images leverage a common library, resulting in significantly smaller sizes compared to traditional operating system images.
Let’s talk about the hierarchical structure of the image and why we should use the hierarchical structure of the image?
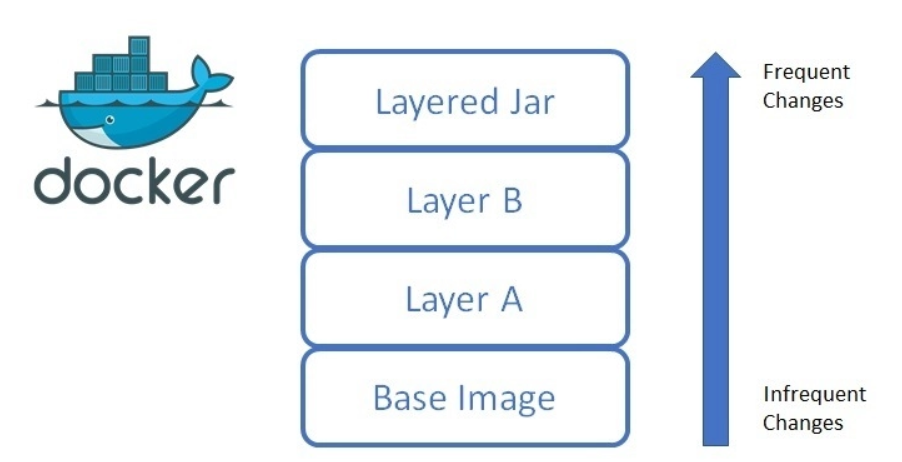
A new image is actually generated layer by layer from the base image. Every time a software is installed, using the RUM command in the dockerfile will add a layer to the existing image, so that the layers are superimposed one by one to form the entire image. So when we docker pull to pull an image, we will see that docker pulls it layer by layer.
One of the biggest benefits of hierarchical organizations is: shared resources. For example, if multiple images are built from the same base image, Docker Host only needs to save one base image on the disk; at the same time, it only needs to load one base image into the memory to serve all containers. And every layer of the image can be shared.
Let’s talk about the copy-on-write feature of containers. Will modifying the contents of the container modify the image?
In Docker, images are layered, with each layer being shareable. Additionally, images are read-only. When a container is started, a new writable layer is created on top of the image. This writable layer is commonly referred to as the “container layer,” while everything below it is termed the “image layer.”
Any modifications made to the container—such as adding, deleting, or modifying files—occur only in the container layer. This is because the container layer is writable, while all image layers beneath it are read-only. Multiple image layers are combined to form a unified file system. If a file exists with the same path in different layers, such as /a, the version in the upper layer will overwrite the one in the lower layer, meaning the user can only access the file /a in the upper layer. Essentially, the container layer presents a superimposed file system to the user.
When adding a file, Docker adds it to the container layer. When reading a file, Docker searches for it in each image layer from top to bottom. Once found, it is copied to the container layer and then read into memory. Similarly, when modifying or deleting a file, Docker searches for it in the image layers, performs the necessary operation, and logs the changes in the container layer.
This process employs a feature called Copy-on-Write, where data is only copied when it needs modification. This ensures that the container layer saves only the altered parts of the image without modifying the image itself.
Briefly describe the entire image building process of Dockerfile
- Begin by creating a directory to store your application and related files.
- Within this directory, create a file named Dockerfile. It’s typically recommended to use this exact filename.
- In the Dockerfile, specify instructions for building the image. These instructions include:
- Using the FROM instruction to specify the base image.
- Using the COPY instruction to copy files from the host into the image.
- Using the RUN instruction to execute commands during the image build process.
- Using ENV to set environment variables.
- Using EXPOSE to specify which ports should be exposed by the container.
- Using WORKDIR to set the current working directory within the container.
- Using CMD to define the command to run when the container starts.
- Once the Dockerfile is written, you can build the image using the docker build -t imageName:tag . command. The dot at the end indicates that the build should be performed in the current directory. If your Dockerfile is not named Dockerfile or located in the current directory, you can use the -f parameter to specify its location: docker build -t ImageName:tag -f /path/to/Dockerfile .
- When you execute the docker build command, Docker sends all files from the current directory to the Docker daemon. The daemon then executes the instructions in the Dockerfile sequentially. During this process, a temporary container is created, and the commands specified by RUN are executed within this container. Once the installation is successful, Docker saves the container as an image using a command similar to docker commit. The temporary container is then deleted, and this process continues, building up the image layer by layer until the final image is successfully created.
An exception occurs when building the Dockerfile image. How to troubleshoot?
During the construction of a Docker image using the Dockerfile, the image is built layer by layer, often leading to the creation of one or more temporary containers. These temporary containers are used to install the application during the build process. If the image building process fails due to an abnormal installation in one of these temporary containers, the container itself may have been cleaned up, but the intermediate image created during the failed build process still remains.
In such cases, we can run the temporary image as a container based on the last successfully built layer at the time of the exception. Then, we can execute the installation command within this container to pinpoint the specific exception that caused the failure. This allows us to troubleshoot and resolve any issues encountered during the image building process.
What are the basic instructions of Dockerfile?

- FROM: Specifies the base image. This must be the first instruction as it defines which base image to use for building the image.
- MAINTAINER: Sets information about the image author, such as name, date, email, and contact information.
- COPY: Copies files from the host into the image.
- ADD: Similar to COPY but also supports automatically decompressing archive files and downloading files from URLs. However, it’s generally recommended to use COPY for file copying.
- ENV: Sets environment variables within the image.
- EXPOSE: Exposes ports used by the container process. It serves as a reminder for users about which ports the container uses.
- VOLUME: Defines data volumes for persistent storage, allowing directories to be mounted.
- WORKDIR: Sets the working directory within the container. If the directory doesn’t exist, it will be created automatically.
- RUN: Executes commands within the container. Each RUN command creates a new image layer and is commonly used for installing software packages.
- CMD: Specifies default commands to run when the container starts. If multiple CMD instructions are provided, only the last one takes effect. Additionally, the CMD instruction can be overridden by parameters passed after
docker run. - ENTRYPOINT: Specifies commands to run when the container starts. Similar to CMD, if multiple ENTRYPOINT instructions are provided, only the last one takes effect. If both CMD and ENTRYPOINT are present, parameters passed after
docker runare passed to ENTRYPOINT as parameters.
How to enter the container? which command to use
There are two ways to enter the container: docker attach and docker exec;
the docker attach command is to attach to the terminal of the container startup command, and docker exec is to start a TTY terminal in the container.
docker run -d centos /bin/bash -c "while true;do sleep 2;echo I_am_a_container;done"
3274412d88ca4f1d1292f6d28d46f39c14c733da5a4085c11c6a854d30d1cde0
docker attach 3274412d88ca4f #attach into the container
Ctrl + c to exit. Ctrl + c will directly close the container terminal. In this way, the container will die if there is no process running in the foreground.
Ctrl + pq exit (will not close the container terminal to stop the container, only exit)
docker exec -it 3274412d88ca /bin/bash #exec enters the container
[root@3274412d88ca /]# ps -ef #Enter the container and start a bash process
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 05:31 ? 00:00:01 /bin/bash -c while true;do sleep 2;echo I_am_a_container;done
root 306 0 1 05:41 pts/0 00:00:00 /bin/bash
root 322 1 0 05:41 ? 00:00:00 /usr/bin/coreutils --coreutils-prog-shebang=sleep /usr/bin/sleep 2
root 323 306 0 05:41 pts/0 00:00:00 ps -ef
[root@3274412d88ca /]#exit #Exit the container, only exit our own bash windowSummary: attach is a terminal that directly enters the container startup command and will not start a new process; exec opens a new terminal in the container and starts a new process; it is generally recommended to exec into the container.
What is k8s ? express your understanding
Kubernetes, often abbreviated as K8s, is an open-source container orchestration system. Its primary purpose is to manage containerized applications efficiently. Kubernetes simplifies the deployment, scaling, and management of containerized applications, providing features for application deployment, scheduling, updates, and maintenance.
In essence, Kubernetes is a tool for orchestrating containers, allowing users to manage the entire lifecycle of containerized applications. This includes creating applications, deploying them, providing services to them, scaling them up or down as needed, and updating them. Kubernetes offers powerful capabilities such as self-healing in case of failures, making it a robust container orchestration system for modern cloud-native applications.
What are the components of k8s and what are their functions?
Kubernetes, often abbreviated as K8s, is composed of two main components: the master node and the worker node. The master node is responsible for managing the cluster, while the worker node is where the containerized applications actually run.
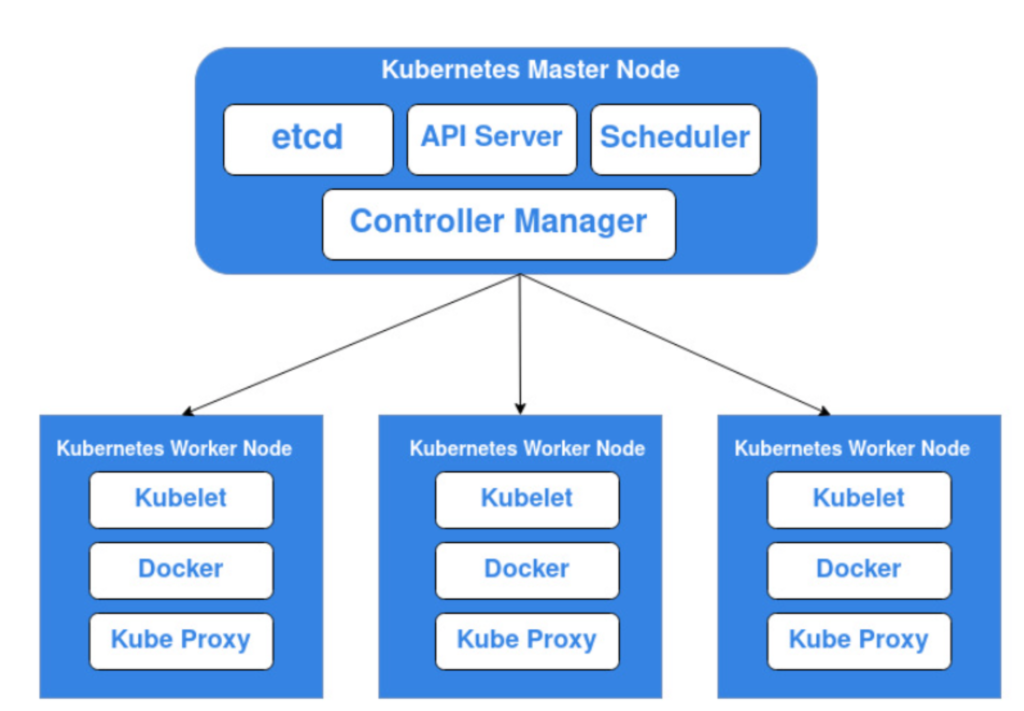
Master Node Components:
- kube-api-server (API Server): This is like the central hub of Kubernetes. It provides a unified entrance for managing the cluster through a RESTful API interface. It handles authentication, authorization, and access control. All interactions between components happen through the API server, and it stores data in the etcd database.
- kube-controller-manager (Controller Manager): This component manages various controllers within Kubernetes. These controllers handle tasks such as managing replica sets, nodes, deployments, and endpoints. The controller manager is responsible for maintaining the desired state of the cluster.
- kube-scheduler (Scheduler): The scheduler is responsible for placing pods onto nodes in the cluster. It uses complex algorithms to determine the best node for a pod based on resource requirements and availability. The scheduler ensures optimal resource utilization and load balancing across the cluster.
- etcd: Etcd is a distributed key-value pair database used for storing cluster state data. It serves as the primary data store for Kubernetes, storing information about resources like pods and services. Multiple etcd instances are typically deployed for high availability.
Worker Node Components:
- kubelet: Each worker node runs a kubelet service process. The kubelet is responsible for managing the lifecycle of pods and containers on the node. It communicates with the master node to receive instructions for creating, updating, or deleting pods. The kubelet also reports node resource usage back to the master.
- kube-proxy: Kube-proxy runs on each worker node and is responsible for implementing pod networking and load balancing. It maintains network rules and provides service discovery and load balancing for applications running in pods. Kube-proxy monitors the API server for changes to services and endpoints and adjusts routing rules accordingly.
- Container Runtime: This is the underlying software responsible for running containers. Kubernetes supports various container runtimes, such as Docker or rkt. Docker is the most popular, but Kubernetes is moving towards other runtimes in newer versions.
What is the port of kube-api-server? How do each pod access kube-api-server?
The kube-api-server runs on ports 8080 and 6443, with 8080 being the HTTP port and 6443 being the HTTPS port. For example, in a Kubernetes cluster installed locally using kubeadm:
- Within the kube-system namespace, there’s a pod named kube-api-master hosting the kube-api-server process. It’s bound to the master host’s IP address and port 6443.
- In the default namespace, there’s a service called kubernetes. This service is exposed externally on port 443, with its target port set to 6443. The IP address of this service corresponds to the first address in the cluster IP address pool.
- The kubernetes service doesn’t specify a label selector in its YAML definition, indicating that the corresponding endpoints are created manually. These endpoints are also named kubernetes and are defined to proxy requests to port 6443 on the master node, which is where the kube-api-server is located.
In summary, other pods access the kube-api-server as follows: after a pod is created, it embeds environment variables containing the IP address and port 443 of the kubernetes service. Requests made to the kubernetes service are then forwarded to port 6443 on the master node, where the kube-api-server is running inside the pod.
What is the role of namespace in k8s?
The role of namespaces in Kubernetes is crucial for achieving resource isolation in multiple environments or enabling multi-tenant resource isolation.
Namespaces provide a way to logically isolate resources within a Kubernetes cluster, allowing for segregated use and management of different resources. Resources with the same name can coexist in different namespaces, providing a scope for resources.
By leveraging Kubernetes’ authorization mechanisms, different namespaces can be assigned to different tenants for management, enabling multi-tenant resource isolation. Additionally, namespaces can be combined with Kubernetes’ resource quota mechanism to limit the resources that different tenants can consume, such as CPU and memory usage, thereby managing the available resources for each tenant effectively.
k8s provides a large number of REST interfaces, one of which is the Kubernetes Proxy API interface. Let’s briefly describe the role of this Proxy interface and how to use it.
The Kubernetes Proxy API interface serves as a proxy for REST requests within a Kubernetes cluster. It allows users to access the REST interface of the kubelet daemon on a node indirectly through the Kubernetes API server. The kubelet process on the node is responsible for handling and responding to these requests.
This Proxy interface is particularly useful for directly accessing individual pods, which can be beneficial for troubleshooting pod-related issues. By using the Proxy interface, users can make REST requests to interact with specific pods within the cluster.
Here are some simple examples of how to use the Proxy interface:
1. View all pod information of the specified node:
http://<kube-api-server>:<api-server-port>/api/v1/nodes/<node-name>/proxy/pods
2. View the physical resource statistics of the specified node:
http://<kube-api-server>:<api-server-port>/api/v1/nodes/<node-name>/proxy/stats
3. View the summary information of the specified node:
http://<kube-api-server>:<api-server-port>/api/v1/nodes/<node-name>/proxy/spec
4. Access the program page of the specified pod:
http://<kube-api-server>:<api-server-port>/api/v1/namespaces/<namespace>/pods/<pod-name>/<pod-service-url>/
5. Access the URL program page of the specified server:
http://<kube-api-server>:<api-server-port>/api/v1/namespaces/<namespace>/services/<svc-name>/<url>/
What is a pod?

In Kubernetes, instead of dealing directly with individual containers, it operates on the concept of multiple containers working together, which forms what is known as a pod. A pod is essentially a group of containers that are tightly coupled and share the same resources and network space. It represents the smallest deployable and manageable unit in Kubernetes.
Pods serve as the fundamental building blocks in Kubernetes. They are the basic unit that users create and deploy within the Kubernetes environment. Other Kubernetes resource objects support the functionality of pods. For instance, pod controllers are used to manage pod objects, services or ingresses expose pod references to the external world, and persistent volumes provide storage for pods.
What is the principle of pod?
In the realm of microservices, containers are typically designed to run a single process. However, if a process spawns child processes, it becomes impractical to contain them within the same isolated container.
What are the characteristics of pod ?
1. Each pod is like an independent logical machine. K8s will assign each pod a unique IP address within the cluster, so each pod has its own IP address, host name, process, etc.;
2. A pod can contain one or more containers. A container is generally designed to run only one process. A pod can only run on a single node. That is, it is impossible for a pod to run across nodes. The life of the pod The cycle is short-lived, which means that the pod may be destroyed at any time (such as node abnormality, pod abnormality, etc.);
2. Each pod has a special pause container called the "root container", also called the info container. The image corresponding to the pause container is part of the k8s platform. In addition to the pause container, each pod also contains one or more Application containers that run business-related components;
3. Containers in a pod share the network namespace;
4. Multiple containers in a pod share the pod IP, which means that the ports occupied by the processes of multiple containers in a pod cannot be the same, otherwise port conflicts will occur in the pod; since each pod has With its own IP and port space, there is no possibility of port conflict between two different pods;
5. Applications should be organized into multiple pods, and each pod only contains closely related components or processes;
6. Pod is the basic unit of expansion and contraction in k8s, which means that expansion and contraction in k8s are for pods, not containers.🔥 [30 % Off CURRENT OFFER ] Kubernetes Certification Coupon , THREE DAYS ONLY Mar 6, 2024 – Mar 8, 2024 !
Kubernetes Certification Coupon (Kubernetes CKAD , CKA and CKS) , Bootcamps, SkillCreds, or Courses .
Coupon: use code IWD24 at checkout
Hurry Up: Offer valid from Mar 6, 2024 – Mar 8, 2024. ⏳
Offer valid from Mar 6, 2024 – Mar 8, 2024. . ⏳
Use code IWD24 at CHECKOUT